What Is the Maximum Number of Synchronizations That Can Be Performed Automatically Per Day?
This topic provides answers to some oftentimes asked questions nigh batch synchronization.
- O&M of batch synchronization nodes
- Why is the connectivity test of a data source successful, but the corresponding batch synchronization node fails to exist run?
- How exercise I alter the resource group that is used to run a data synchronization node in Data Integration?
- How do I locate and handle muddy data?
- Common plug-in errors
- How do I handle a dirty data error that is caused past encoding format configuration problems or garbled characters?
- What exercise I practice if the error message [TASK_MAX_SLOT_EXCEED]:Unable to notice a gateway that meets resource requirements. xx slots are requested, but the maximum is 16 slots. is returned?
- What practise I practise if a server-side request forgery (SSRF) attack is detected in a node?
- What do I do if the error message OutOfMemoryError: Java heap space is returned when I run a batch synchronization node?
- What do I practice if the same batch synchronization node fails to be run occasionally?
- What practice I do if the fault message Duplicate entry '30' for central 'uk_uk_op' is returned when I run a batch synchronization node?
- What do I practise if the error message plugin xx does not specify cavalcade is returned when I run a batch synchronization node?
- What practise I do if a synchronization node fails to exist run because the name of a column in the source table is a keyword?
- Errors of specific plug-ins
- What do I exercise if an mistake occurs when I add a MongoDB data source as the root user?
- The authDB database used past MongDB is the admin database. How practice I synchronize information from business databases?
- How do I convert the values of the variables in the query parameter into values in the timestamp format when I synchronize incremental information from a table of a MongDB database?
- What do I exercise if the error message AccessDenied The saucepan yous access does non belong to y'all. is returned when I read information from an OSS bucket?
- Is an upper limit configured for the number of OSS objects that tin be read?
- What practice I do if the error message Lawmaking:[RedisWriter-04], Description:[Dirty data]. - source cavalcade number is in valid! is returned when I write information to Redis in hash way?
- What do I do if the following error message is returned when I read data from or write data to ApsaraDB RDS for MySQL: Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout/net_read_timeout,' on the server.?
- What practise I do if the mistake message The last parcel successfully received from the server was 902,138 milliseconds ago is returned when I read data from MySQL?
- What do I do if an error occurs when I read information from PostgreSQL?
- What do I do if the error message Communications link failure is returned?
- What do I do if the error bulletin The download session is expired. is returned when I read data from a MaxCompute table?
- What do I exercise if the error message Error writing request torso to server is returned when I write data to a MaxCompute table?
- What do I exercise if data fails to be written to DataHub because the corporeality of data that I want to write to DataHub at a time exceeds the upper limit?
- What do I exercise if the JSON information returned based on the path:[] condition is not of the Array type when I use RestAPI Writer to write data?
- Batch synchronization
- How do I customize tabular array names in a batch synchronization node?
- What practise I do if the tabular array that I want to select does non announced in the Table drop-down listing in the Source department when I configure a batch synchronization node?
- What are the items that I must have notation of when I utilize the Add together characteristic in a synchronization node that reads data from the MaxCompute table?
- How do I read data in segmentation key columns from a MaxCompute table?
- How practise I synchronize data from multiple partitions of a MaxCompute table?
- What do I do if a synchronization node fails to be run because the proper name of a cavalcade in the source tabular array is a keyword?
- Why is no information obtained when I read data from a LogHub tabular array whose columns contain data?
- Why is some data missing when I read information from a LogHub data source?
- What do I do if the fields that I read based on the field mapping configuration in LogHub are not the expected fields?
- I configured the endDateTime parameter to specify the end time for reading from a Kafka data source, but some information that is returned is generated at a time signal later than the specified end fourth dimension. What exercise I do?
- How exercise I remove the random strings that appear in the data I write to OSS?
- How does the organization synchronize data from a MySQL data source on which sharding is performed to a MaxCompute table?
Why is the connectivity test of a data source successful, only the respective batch synchronization node fails to exist run?
- If the data source has passed the connectivity examination, y'all can examination the connectivity again to brand certain that the resource group that y'all use is connected to the data source and the information source remains unchanged.
- Bank check whether the resources group that is connected to the data source is the same as the resources group that y'all utilise to run a batch synchronization node.
Check the resources that is used to run a node:
- If the node is run on the shared resources group for Information Integration, the log contains the following information:
running in Pipeline[basecommon_ group_xxxxxxxxx]. - If the node is run on a custom resource grouping for Data Integration, the log contains the following information:
running in Pipeline[basecommon_xxxxxxxxx]. - If the node is run on an exclusive resource group for Data Integration, the log contains the post-obit information:
running in Pipeline[basecommon_S_res_group_xxx].
- If the node is run on the shared resources group for Information Integration, the log contains the following information:
- If the node that is scheduled to run in the early forenoon occasionally fails but reruns successfully, check the load of the data source at the time when the failure occurred.
How do I change the resource group that is used to run a data synchronization node in Data Integration?
- Method 1: Change the resource group that is used to run a information synchronization node in Data Integration on the Cycle Task page in Operation Centre.

- Method 2: Alter the resource group that is used to run a data synchronization node in Data Integration on the Resource Group configuration tab in DataStudio.
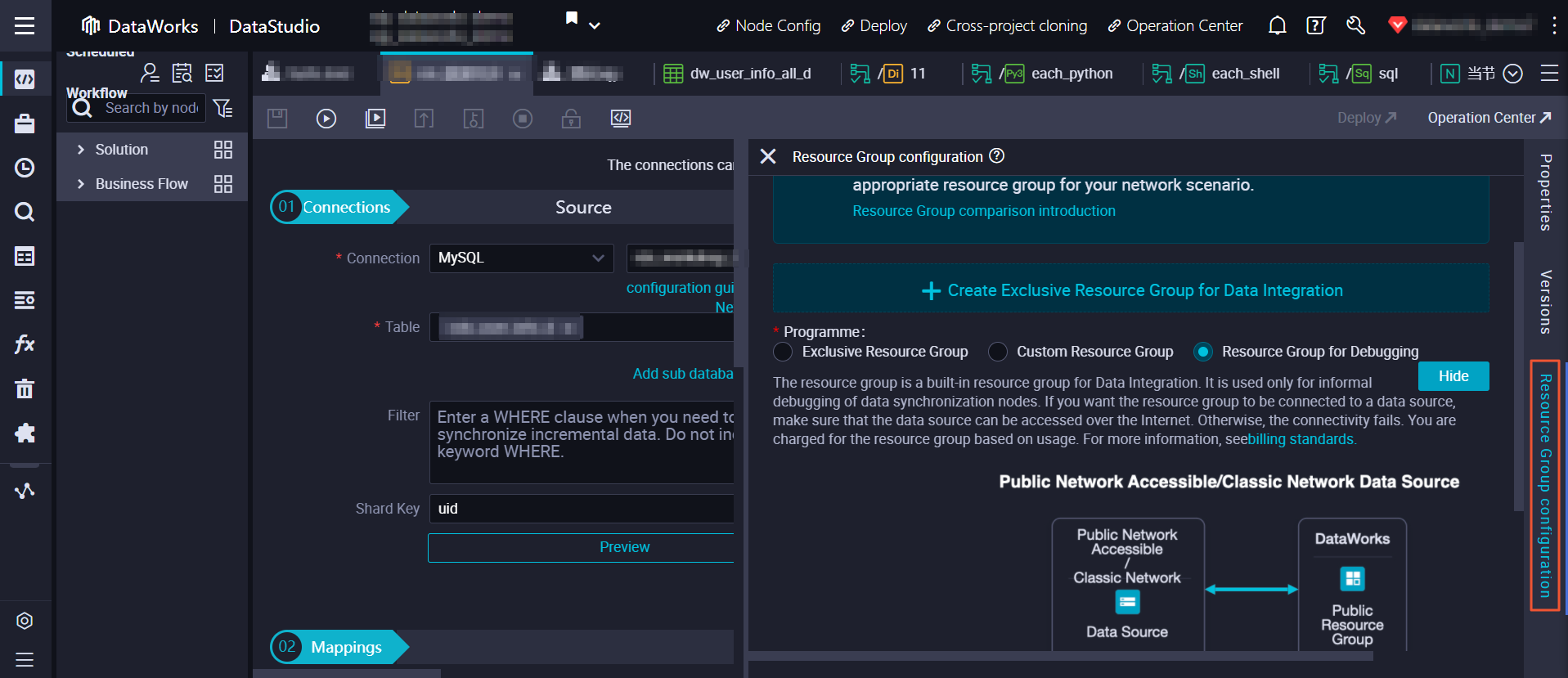
Note If you utilise method ii, you must commit and deploy the node to brand the alter take event.
How practice I locate and handle dirty data?
Definition: If an exception occurs when a single data tape is written to the destination, the data record is considered as dirty data. Therefore, data records that fail to be written to the destination are considered as dirty information.
Impact: Dirty data fails to be written to the destination. You can control whether dirty data tin can exist generated and the maximum number of muddied data records that tin exist generated. By default, muddy data is allowed in Data Integration. You tin specify the maximum number of dirty data records that can be generated when you configure a synchronization node. For more information, see Configure channel control policies.
- Dirty data is allowed in a synchronization node: If a dingy data tape is generated, the synchronization node continues to run. All the same, the muddy data tape is discarded and is not written to the destination.
- The maximum number of dirty data records that can exist generated is specified for a synchronization node:
- If you set the maximum number of dirty information records that can be generated to 0, the synchronization node fails and exits when a dirty data record is generated.
- If yous gear up the maximum number of dirty information records that tin be generated to x, the synchronization node fails and exits when the number of dirty data records exceeds 10. The synchronization node continues to run if the number of dirty data records is less than x. However, the dirty information records are discarded and are not written to the destination.
Analysis of dirty data generated during data synchronization:
- Problem description: The following fault bulletin is returned:
{"message":"Muddy data is found in the data that is to exist written to the destination MaxCompute table: The [third] field contains dirty data. Check and correct the data, or increment the threshold value and ignore this dirty data record.","tape":[{"byteSize":0,"index":0,"type":"Engagement"},{"byteSize":0,"index":i,"type":"DATE"},{"byteSize":one,"index":2,"rawData":0,"type":"LONG"},{"byteSize":0,"index":3,"type":"Cord"},{"byteSize":i,"alphabetize":4,"rawData":0,"type":"LONG"},{"byteSize":0,"index":v,"blazon":"STRING"},{"byteSize":0,"index":6,"type":"String"}. - The logs testify that the 3rd field contains muddied data. You can identify the cause of dirty data based on the post-obit scenarios:
- If dirty data is reported by a writer, you lot must check the CREATE TABLE statement of the author. The information size of the specified field in the destination MaxCompute table is less than the data size of the same field in the source MySQL table.
- If you lot desire to write information from the source to the destination, the post-obit requirements must be met: 1. The information type in source columns must match the data type in destination columns. For case, data of the VARCHAR type in source columns cannot exist written to the destination columns that contain data of the INT type. 2. The size of data defined by the data blazon of destination columns must be sufficient to receive the data in the mapping columns in the source. For case, you can write information of the LONG, VARCHAR, or DOUBLE type from the source to the columns that contain information of the Cord or TEXT type.
- If a dirty data fault is not clear, you must copy and print out muddied data records, observe the data, and then compare the data type of the records with the data type in destination columns to identify dirty data records.
byteSize: the number of bytes. alphabetize:25: the 26th field. rawData: a specific value. type: the data type.{"byteSize":28,"index":25,"rawData":"ohOM71vdGKqXOqtmtriUs5QqJsf4","type":"STRING"}
How exercise I handle a dingy information error that is caused by encoding format configuration problems or garbled characters?
- Problem description:
If data contains emoticons, a dingy data fault message similar to the post-obit error message may be returned when y'all synchronize the information:
[13350975-0-0-writer] ERROR StdoutPluginCollector - muddy data {"exception":"Incorrect string value: '\\xF0\\x9F\\x98\\x82\\xE8\\xA2...' for column 'introduction' at row one","record":[{"byteSize":8,"index":0,"rawData":9642,"type":"LONG"},}],"blazon":"writer"}. - Crusade:
- utf8mb4 is not configured for a information source. As a effect, an error is reported when data that contains emoticons is synchronized.
- Data in the source contains garbled characters.
- The encoding format is different betwixt a data source and a synchronization node.
- The encoding format of the browser is different from the encoding format of the data source or synchronization node. Every bit a effect, the preview fails or the previewed information contains garbled characters.
- Solution:
The solution varies based on the cause.
- If data in the source contains garbled characters, procedure the data before you run a synchronization node.
- If the encoding format of the information source is unlike from the encoding format of the synchronization node, modify the configuration for the encoding format of the data source to be the same equally the encoding format of the synchronization node.
- If the encoding format of the browser is different from the encoding format of the information source or synchronization node, modify the configuration for the encoding format of the browser and make sure that the encoding format is the same every bit the encoding format of the data source and synchronization node. And then, preview the data.
- If you add a data source by using a Java Database Connectivity (JDBC) URL, add the encoding format utf8mb4 to the JDBC URL. JDBC URL sample:
jdbc:mysql://xxx.x.ten.x:3306/database?com.mysql.jdbc.faultInjection.serverCharsetIndex=45. - If you add a data source by using an example ID, suffix the information source name with the encoding format, such as
database?com.mysql.jdbc.faultInjection.serverCharsetIndex=45. - Change the encoding format of the data source to utf8mb4. For example, you can change the encoding format of the ApsaraDB RDS information source in the ApsaraDB RDS console.
Note Run the following command to set the encoding format of the Apsara RDS data source to utf8mb4:
gear up names utf8mb4. Run the following command to view the encoding format of the Apsara RDS data source:show variables like 'char%'.
What do I practise if the error bulletin [TASK_MAX_SLOT_EXCEED]:Unable to discover a gateway that meets resource requirements. twenty slots are requested, simply the maximum is xvi slots. is returned?
- Crusade:
The number of nodes that are run in parallel is set to an excessively large value and the resources are not sufficient to run the nodes.
- Solution:
Reduce the number of batch synchronization nodes that are run in parallel.
- If yous configure a batch synchronization node past using the codeless user interface (UI), prepare Expected Maximum Concurrency to a smaller value in the Channel pace. For more than information, see Configure channel control policies.
- If you configure a batch synchronization node by using the code editor, set concurrent to a smaller value when you configure the aqueduct control policies. For more than data, meet Configure channel command policies.
What practise I exercise if a server-side request forgery (SSRF) attack is detected in a node?
If the information source is added by using a virtual private deject (VPC) accost, you cannot use the shared resources group for Data Integration to run a node. Instead, you can use an sectional resource group for Data Integration to run the node. For more information about an exclusive resource group for Data Integration, see Create and utilise an exclusive resource group for Information Integration.
What do I do if the error bulletin OutOfMemoryError: Java heap space is returned when I run a batch synchronization node?
Solution:
- If yous use an exclusive resource group for Data Integration to run a node, you can suit the values of the Coffee Virtual Machine (JVM) parameters.
- If the reader or author that y'all use supports the batchsize or maxfilesize parameter, fix the batchsize or maxfilesize parameter to a smaller value.
If you want to check whether a reader or writer supports the batchsize or maxfilesize parameter, encounter Supported data sources, readers, and writers.
- Reduce the number of nodes that are run in parallel.
- If you configure a batch synchronization node by using the codeless user interface (UI), set up Expected Maximum Concurrency to a smaller value in the Channel step. For more information, see Configure channel control policies.
- If y'all configure a batch synchronization node by using the code editor, fix concurrent to a smaller value when you configure the channel control policies. For more information, see Configure aqueduct control policies.
- If you synchronize files, such as Object Storage Service (OSS) files, reduce the number of files that you want to read.
What practise I practice if the same batch synchronization node fails to be run occasionally?
If a batch synchronization node occasionally fails to be run, a possible cause is that the whitelist configuration of the data source for the node is incomplete.
- Use an exclusive resources group for Data Integration to run the batch synchronization node:
- If you have added the IP address of the ENI (Elastic Network Interface) of the exclusive resource group for Information Integration to the whitelist of the data source, when the resources grouping is scaled out, you must add the ENI IP address to the whitelist again to update the whitelist.
- We recommend that you directly add the CIDR block of the vSwitch to which the exclusive resources group for Data Integration is bound to the whitelist of the data source. Otherwise, you must update the ENI IP address each time the resources grouping is scaled out. For more than data, see Configure a whitelist.
- Use the shared resource group for Data Integration to run the batch synchronization node:
Make certain that all the CIDR blocks of the machines that are used for data synchronization in the region where the shared resource group for Data Integration resides are added to the whitelist of the data source. For more information, see Add the IP addresses or CIDR blocks of the servers in the region where the DataWorks workspace resides to the whitelist of a data source.
If the configuration of the whitelist for the data source is complete, check whether the connexion between the data source and Data Integration is interrupted due to the heavy load of the data source.
What do I exercise if an mistake occurs when I add a MongoDB data source as the root user?
Change the username. You must employ the name of the user that has performance permissions on the data source instead of the root user.
For example, if y'all want to synchronize data of the name table in the exam data source, apply the name of the user that has operation permissions on the test data source.
The authDB database used by MongDB is the admin database. How do I synchronize data from business databases?
Enter the proper noun of a business database when you configure a data source to make sure that the user that yous use has the required permissions on the business database. If the error message "auth failed" is returned when you test the connectivity of the data source, ignore the error message. If you configure a synchronization node by using the code editor, add the "adthDb":"admin" parameter to the JSON configurations of the synchronization node.
How do I convert the values of the variables in the query parameter into values in the timestamp format when I synchronize incremental data from a table of a MongDB database?
Utilize assignment nodes to convert data of the DATE type into information of the TIMESTAMP format and utilize the timestamp value as an input parameter for data synchronization from MongDB. For more data, run across How do I synchronize incremental data that is in the timestamp format from a tabular array of a MongDB database?
What do I do if the error message AccessDenied The bucket you admission does not belong to you. is returned when I read data from an OSS bucket?
The user that is configured for OSS and has the AccessKey pair does non have permissions to admission the bucket. Grant the user permissions to access the saucepan.
Is an upper limit configured for the number of OSS objects that can be read?
In Data Integration, the number of OSS objects that tin be read from OSS past OSS Reader is non limited. The maximum number of OSS objects that can be read is determined by the JVM parameters that are configured for a synchronization node. To prevent out of memory (OOM) errors, we recommend that y'all do non set the Object parameter to an asterisk (*).
What do I practice if the fault message Code:[RedisWriter-04], Description:[Dirty information]. - source column number is in valid! is returned when I write data to Redis in hash mode?
- Cause:
If yous desire to store data in Redis in hash mode, make sure that attributes and values are generated in pairs. Example:
odpsReader: "column":[ "id", "name", "age", "address", ]. In Redis, if RedisWriter: "keyIndexes":[ 0 ,one] is used, id and proper noun are used equally keys, age is used as an aspect, and address is used as a value in Redis. If the source is MaxCompute and merely two columns are configured, yous cannot store the Redis cache in hash mode, and an error is reported. - Solution:
If y'all want to apply simply two columns, you must store data in Redis by using the string mode. If yous need to store information in hash mode, you must configure at least three columns in the source.
What do I exercise if the post-obit error message is returned when I read data from or write information to ApsaraDB RDS for MySQL: Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout/net_read_timeout,' on the server.?
- Cause:
- net_read_timeout: If the error message contains this parameter, the execution time of an SQL argument exceeded the maximum execution time allowed past ApsaraDB RDS for MySQL. The SQL argument is 1 of the multiple SQL statements that are obtained afterwards a single data conquering SQL argument is equally divide based on the splitpk parameter when you run a synchronization node to read data from the MySQL data source.
- net_write_timeout: If the fault bulletin contains this parameter, the timeout period in which the system waits for a block to exist written to a data source is too pocket-size.
- Solution:
Add the net_write_timeout or net_read_timeout parameter to the URL of the ApsaraDB RDS for MySQL database and set the parameter to a larger value. You lot tin can also set the net_write_timeout or net_read_timeout parameter to a larger value in the ApsaraDB RDS console.
- Proffer:
If possible, configure the synchronization node to be rerun automatically.
Instance: jdbc:mysql://192.168.1.ane:3306/lizi?useUnicode=true&characterEncoding=UTF8&net_write_timeout=72000
What practise I do if the fault bulletin The last package successfully received from the server was 902,138 milliseconds agone is returned when I read data from MySQL?
In this case, the CPU utilization is normal just the memory usage is high. As a event, the data source is disconnected from Data Integration.
If you confirm that the synchronization node can be rerun automatically, we recommend that y'all configure the node to be automatically rerun if an error occurs. For more data, see Configure time properties.
What exercise I do if an error occurs when I read information from PostgreSQL?
- Problem description: The error message
org.postgresql.util.PSQLException: FATAL: terminating connection due to conflict with recoveryis returned when I employ a batch synchronization tool to synchronize information from PostgreSQL. - Cause: This error occurs because the arrangement takes a long fourth dimension to obtain data from the PostgreSQL database. To resolve this issue, specify the max_standby_archive_delay and max_standby_streaming_delay parameters in the code of the synchronization node. For more information, see Standby Server Events.
What practise I do if the fault bulletin Communications link failure is returned?
- Read data from a data source:
- Problem description:
The following error message is returned when data is read from a data source:
Communications link failure The concluding packet successfully received from the server was 7,200,100 milliseconds agone. The concluding packet sent successfully to the server was 7,200,100 milliseconds ago. - com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure. - Cause:
Irksome SQL queries result in timeout when yous read data from MySQL.
- Solution:
- Check whether the WHERE clause is specified to make certain that an alphabetize is added for the filter field.
- Bank check whether a large amount of data exists in the source tabular array. If a big amount of data exists in the source tabular array, we recommend that you run multiple nodes to execute the SQL queries.
- Bank check the database logs to find which SQL queries are delayed and contact the database administrator to resolve the issue.
- Problem description:
- Write information to a data source:
- Trouble description:
The following error message is returned when data is written to a data source:
Caused by: java.util.concurrent.ExecutionException: ERR-CODE: [TDDL-4614][ERR_EXECUTE_ON_MYSQL] Fault occurs when execute on GROUP 'thirty' ATOM 'dockerxxxxx_xxxx_trace_shard_xxxx': Communications link failure The last parcel successfully received from the server was 12,672 milliseconds ago. The last packet sent successfully to the server was 12,013 milliseconds ago. More.... - Cause:
A socket timeout occurred due to dull SQL queries. The default value of the SocketTimeout parameter of Taobao Distributed Data Layer (TDDL) connections is 12 seconds. If the execution time of an SQL statement on a MySQL client exceeds 12 seconds, a TDDL-4614 mistake is returned. This mistake occasionally occurs when the data volume is large or the server is decorated.
- Solution:
- We recommend that you lot rerun the synchronization node after the database becomes stable.
- Contact the database ambassador to conform the value of the SocketTimeout parameter.
- Trouble description:
What practise I do if the error message Duplicate entry 'xxx' for fundamental 'uk_uk_op' is returned when I run a batch synchronization node?
- Problem description: The following error message is returned:
Mistake updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Duplicate entry 'cfc68cd0048101467588e97e83ffd7a8-0' for key 'uk_uk_op'. - Possible cause: In Data Integration, different instances of the same synchronization node cannot exist run at the same time. Therefore, multiple synchronization instances that are configured based on the aforementioned JSON configurations cannot be run at the same fourth dimension. For a synchronization node whose instances are run at 5-infinitesimal intervals, the instance that is scheduled to run at 00:00 and the instance that is scheduled to run at 00:05 are both run at 00:05 due to a delay caused by the ancestor node of the synchronization node. As a consequence, one of the instances fails to exist run. This issue may occur if you backfill information for or rerun a synchronization node that is running.
- Solution: Stagger the running fourth dimension of instances. We recommend that you lot configure nodes that are scheduled to run past hour to depend on their instances in the final cycle. For more information, run into Scenario 2: Configure scheduling dependencies for a node that depends on last-wheel instances.
What do I do if the error bulletin plugin twenty does not specify column is returned when I run a batch synchronization node?
A possible cause is that the field mapping for the batch synchronization node is incorrect or the cavalcade parameter is incorrectly configured in a reader or writer.
- Check whether the mapping betwixt the source fields and the destination fields is configured.
- Check whether the column parameter is configured in a reader or writer based on your business requirements.
What do I do if the error message The download session is expired. is returned when I read data from a MaxCompute table?
- Trouble description:
Code:DATAX_R_ODPS_005:Failed to read data from a MaxCompute tabular array, Solution:[Contact the administrator of MaxCompute]. RequestId=202012091137444331f60b08cda1d9, ErrorCode=StatusConflict, ErrorMessage=The download session is expired. - Cause:
If yous want to read data from a MaxCompute tabular array, you must run a Tunnel command in MaxCompute to upload and download data. On the server, the lifecycle for each Tunnel session spans 24 hours after the session is created. If a batch synchronization node is run for more than 24 hours, it fails to be run and exits. For more information almost the Tunnel service, see Usage notes.
- Solution:
You can increase the number of batch synchronization nodes that can exist run in parallel or configure the volume of information to be synchronized to make sure that the volume of data can be synchronized inside 24 hours.
What do I do if the error message Error writing request body to server is returned when I write data to a MaxCompute table?
- Trouble description:
Code:[OdpsWriter-09], Clarification:[Failed to write data to the destination MaxCompute tabular array.]. - Failed to write Block 0 to the destination MaxCompute tabular array, uploadId=[202012081517026537dc0b0160354b]. Contact the administrator of MaxCompute. - java.io.IOException: Fault writing request body to server. - Cause:
- Cause 1: The information type is incorrect. The source data does not comply with MaxCompute information type specifications. For case, the value 4.2223 cannot exist written to the destination MaxCompute tabular array in the format of DECIMAL(precision,calibration), such equally DECIMAL(18,10).
- Crusade 2: The MaxCompute block is abnormal or the communication is aberrant.
- Solution:
Catechumen the data type of the data that is to be synchronized into a data type that is supported past the destination. If an error is still reported subsequently you convert the data type, you tin can submit a ticket for troubleshooting.
What do I practise if information fails to be written to DataHub considering the amount of data that I desire to write to DataHub at a time exceeds the upper limit?
- Trouble description:
Error JobContainer - Exception when job runcom.alibaba.datax.mutual.exception.DataXException: Lawmaking:[DatahubWriter-04], Description:[Failed to write data to DataHub.]. - com.aliyun.datahub.exception.DatahubServiceException: Record count 12498 exceed max limit 10000 (Status Lawmaking: 413; Error Code: TooLargePayload; Request ID: 20201201004200a945df0bf8e11a42) - Cause:
The amount of information that y'all desire to write to DataHub at a fourth dimension exceeds the upper limit that is allowed past DataHub. The post-obit parameters specify the maximum corporeality of data that tin can be written to DataHub:
- maxCommitSize: specifies the maximum amount of the buffered data that Data Integration can accumulate before information technology commits the data to the destination. Unit of measurement: MB. The default value is 1048576, in bytes, which is 1 MB.
- batchSize: specifies the maximum number of the buffered data records that a unmarried synchronization job can accumulate before it commits the information records to the destination.
- Solution:
Gear up the maxCommitSize and batchSize parameters to smaller values.
How practice I customize tabular array names in a batch synchronization node?
The tables from which you lot want to synchronize data are named in a consequent format. For example, the tables are named by date and the table schema is consistent, such as orders_20170310, orders_20170311, and orders_20170312. You tin specify custom table names by using the scheduling parameters specified in Create a sync node by using the code editor. This style, the synchronization node automatically reads tabular array data of the previous day from the source every morning.
For example, if the current day is March 15, 2017, the synchronization node can automatically read information of the orders_20170314 tabular array from the source. 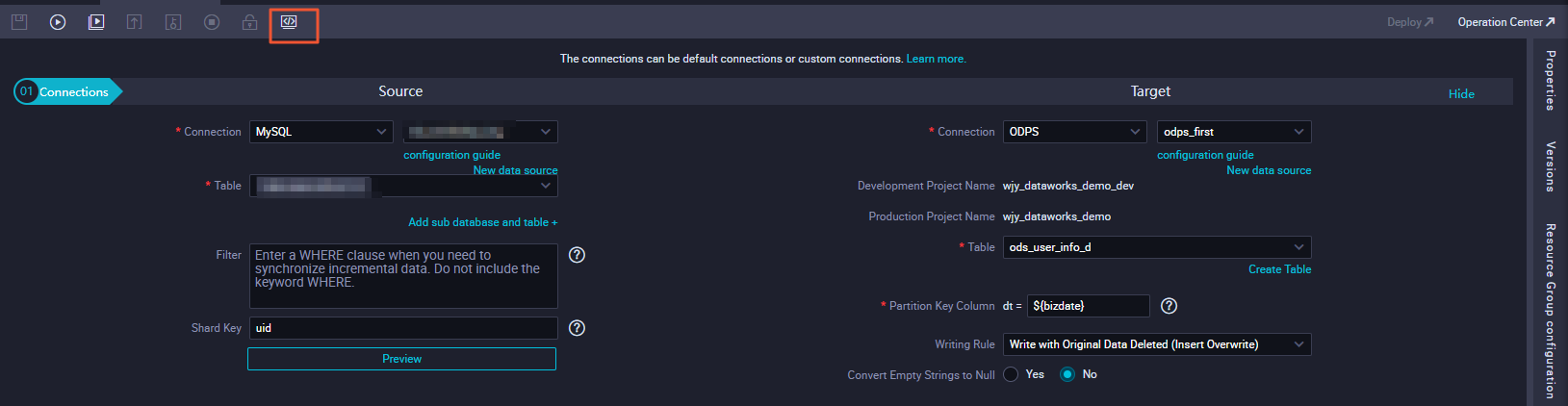
In the lawmaking editor, use a variable to specify the name of a source table, such as orders_${tablename}. The tables are named by date. If you lot want the synchronization node to read information of the previous day from the source every day, assign the value ${yyyymmdd} to the ${tablename} variable in the parameter configurations of the synchronization node.
What do I do if the table that I want to select does non appear in the Table drop-down listing in the Source section when I configure a batch synchronization node?
When y'all configure a batch synchronization node, the Tabular array driblet-down list in the Source section displays simply the first 25 tables in the selected data source by default. If the selected information source contains more than 25 tables and the table that you lot desire to select does not appear in the Table drib-downwardly list, enter the proper noun of the table in the Table field. Yous can likewise configure the batch synchronization node in the lawmaking editor.
What are the items that I must take note of when I apply the Add feature in a synchronization node that reads information from the MaxCompute table?
- You can enter constants. Each constant must exist enclosed in a pair of single quotation marks ('), such as 'abc' and '123'.
- You can use the Add feature together with scheduling parameters, such every bit '${bizdate}'. For more information near how to use scheduling parameters, run into Configure scheduling parameters.
- You can specify the partition fundamental columns from which you want to read information, such equally the division key cavalcade pt.
- If the field that you entered cannot be parsed, the value of Blazon for the field is Custom.
- MaxCompute functions are non supported.
- If the value of Type for the fields that you lot manually added, such every bit the partition key columns of MaxCompute tables, is Custom, synchronization nodes can still be run although the partition key columns cannot be previewed in LogHub.
How do I read data in sectionalization key columns from a MaxCompute table?
Add a data record in the field mapping configuration area, and specify the proper noun of a division key column, such as pt.
How practice I synchronize information from multiple partitions of a MaxCompute tabular array?
Locate the partitions from which you want to read data.
- You lot can use Linux Crush wildcards to specify the partitions. An asterisk (*) indicates zip or multiple characters, and a question mark (?) indicates a single graphic symbol.
- The partitions that you specify must exist in the source table. Otherwise, the system reports an mistake for the synchronization node. If you want the synchronization node to exist successfully run fifty-fifty if the partitions that you specify do not exist in the source tabular array, use the code editor to modify the code of the node. In add-on, you must add together
"successOnNoPartition": trueto the configuration of MaxCompute Reader.
For example, the partitioned table test contains four partitions: pt=one,ds=hangzhou, pt=one,ds=shanghai, pt=2,ds=hangzhou, and pt=2,ds=beijing. In this case, you can fix the partition parameter based on the post-obit instructions:
- To read data from the partition pt=1,ds=hangzhou, specify
"segmentation":"pt=1,ds=hangzhou". - To read data from all the ds partitions in the pt=ane division, specify
"partition":"pt=ane,ds=*". - To read data from all the partitions in the test tabular array, specify
"partition":"pt=*,ds=*".
You tin can too perform the post-obit operations in the lawmaking editor to specify other conditions based on which data is read from partitions:
- To read data from the partition that stores the largest amount of data, add
/*query*/ ds=(select MAX(ds) from DataXODPSReaderPPR)to the configuration of MaxCompute Reader. - To filter data based on filter weather condition, add
/*query*/ pt+Expressionto the configuration of MaxCompute Reader. For case,/*query*/ pt>=20170101 and pt<20170110indicates that you desire to read the data that is generated from January one, 2022 to January 9, 2022 from all the pt partitions in the test table.
Note
MaxCompute Reader processes the content that follows /*query*/ as a WHERE clause.
What exercise I exercise if a synchronization node fails to be run because the name of a column in the source tabular array is a keyword?
- Cause: The column parameter contains reserved fields or fields whose names start with a number.
- Solution: Use the lawmaking editor to configure a synchronization node in Data Integration and escape special fields in the configuration of the column parameter. For more information about how to employ the code editor to configure a synchronization node, come across Create a sync node by using the code editor.
- MySQL uses grave accents (`) equally escape characters to escape keywords in the post-obit format:
`Keyword`. - Oracle and PostgreSQL use double quotation marks (") equally escape characters to escape keywords in the following format:
"Keyword". - SQL Server uses brackets ([]) as escape characters to escape keywords in the following format:
[Keyword].
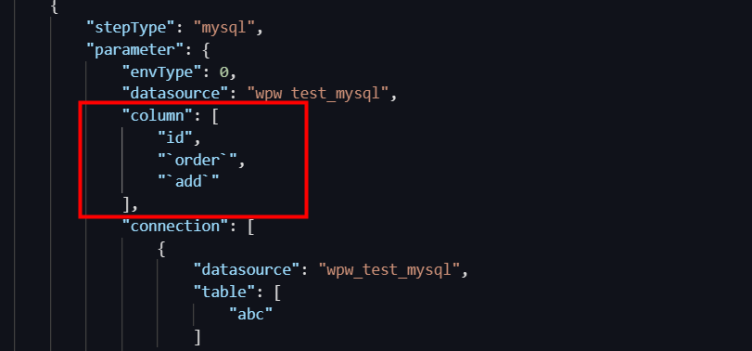
- MySQL uses grave accents (`) equally escape characters to escape keywords in the post-obit format:
- A MySQL data source is used in the following example:
- Execute the following statement to create a tabular array named aliyun, which contains a column named tabular array:
create table aliyun (`tabular array` int ,msg varchar(10)); - Execute the following argument to create a view and assign an allonym to the table column:
create view v_aliyun every bit select `tabular array` every bit col1,msg as col2 from aliyun;Annotation
- MySQL uses table every bit a keyword. If the name of a column in the source table is table, an error is reported during data synchronization. In this case, you must create a view to assign an alias to the tabular array column.
- We recommend that you lot practise not use a keyword as the name of a cavalcade.
- Yous can execute the preceding argument to assign an alias to the cavalcade whose name is a keyword. When you lot configure a synchronization node, use the v_aliyun view to replace the aliyun table.
- Execute the following statement to create a tabular array named aliyun, which contains a column named tabular array:
Why is no data obtained when I read data from a LogHub tabular array whose columns contain information?
In LogHub Reader, column names are instance-sensitive. Check for the cavalcade proper noun configuration in LogHub Reader.
Why is some data missing when I read data from a LogHub data source?
In Data Integration, a synchronization node reads information from a LogHub data source at the time when the data is generated in LogHub. Check whether the value of the metadata field receive_time, which is configured for reading data, is within the fourth dimension range specified for the synchronization node in the LogHub console.
What do I practise if the fields that I read based on the field mapping configuration in LogHub are not the expected fields?
Manually modify the configuration of the column parameter in the LogHub console.
I configured the endDateTime parameter to specify the cease time for reading from a Kafka data source, but some information that is returned is generated at a time bespeak later than the specified end time. What do I do?
Kafka Reader reads data from a Kafka data source in batches. If information that is generated later than the time specified by endDateTime is plant in a batch of read information, Kafka Reader stops reading data. Even so, the information generated later on than the cease time is also written to the destination.
- You can prepare the skipExceedRecord parameter to specify whether to write such data to the destination. For more data, run across Kafka Reader. To prevent data loss, nosotros recommend that y'all gear up the skipExceedRecord parameter to false to ensure that the data generated later on than the stop time is not skipped.
- Yous tin can employ the max.poll.records parameter in Kafka to specify the corporeality of information to poll for at the same time. Configure this parameter and the number of synchronization nodes that can be run in parallel to command the excess data book that is allowed. The allowed excess volume of information is calculated based on the following formula: Allowed backlog data volume < max.poll.records × Number of synchronization nodes that can be run in parallel.
How do I remove the random strings that appear in the data I write to OSS?
When y'all employ OSS Writer to write files to OSS, take annotation of the name prefixes of the files. OSS simulates the directory structure by adding prefixes and delimiters to file names, such as "object": "datax". This way, the names of the files kickoff with datax and cease with random strings. The number of files determines the number of tasks that a synchronization node is split into.
If yous exercise non want to use a random universally unique identifier (UUID) every bit the suffix, nosotros recommend that you set the writeSingleObject parameter to true. For more data, come across the description of the writeSingleObject parameter in OSS Writer.
For more than information, encounter OSS Writer.
How does the organization synchronize data from a MySQL data source on which sharding is performed to a MaxCompute table?
For more information about how to configure MySQL Reader to read data from a MySQL information source, see MySQL Reader.
What do I do if the JSON information returned based on the path:[] status is not of the ARRAY type when I use RestAPI Writer to write information?
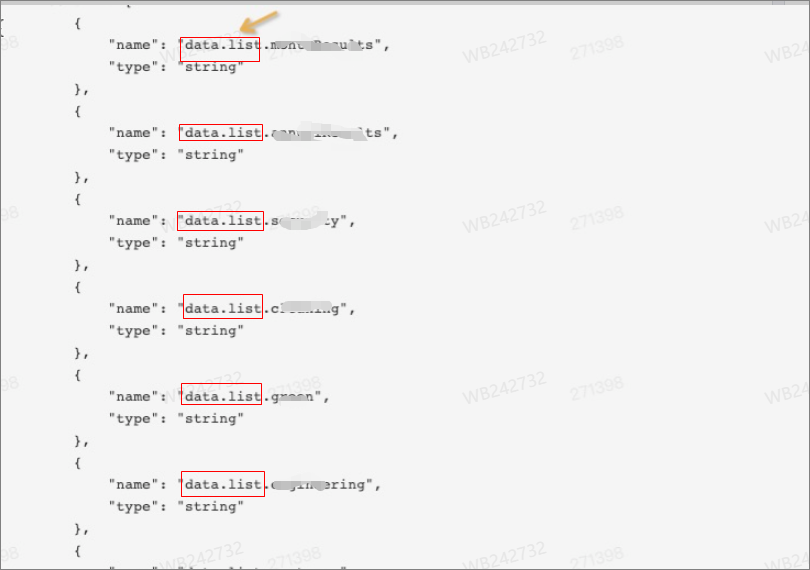
The dataMode parameter tin can exist set up to oneData or multiData for RestAPI Author. If y'all desire to apply RestAPI Writer to write multiple data records, set dataMode to multiData. For more information, see RestAPI Author. You must besides add the dataPath:"data.listing" parameter to the script of RestAPI Reader. 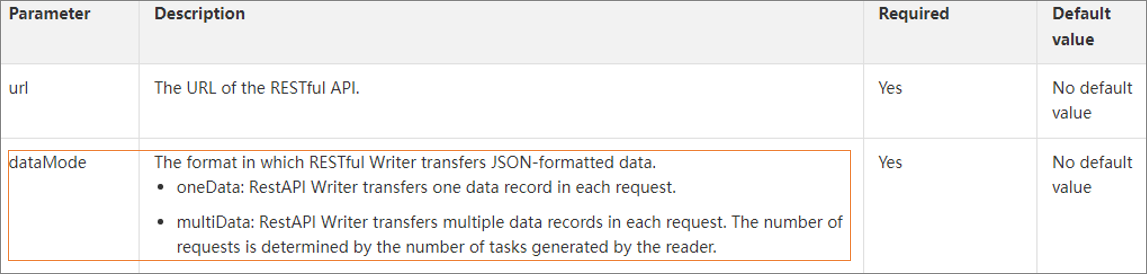
Detect Practice not prefix a column name with data.listing when you configure the column parameter. The following figure shows column names that are prefixed past data.list.
Source: https://www.alibabacloud.com/help/en/doc-detail/146663.htm
Belum ada Komentar untuk "What Is the Maximum Number of Synchronizations That Can Be Performed Automatically Per Day?"
Posting Komentar